はじめに 〜記事執筆のきっかけ〜
先日、以下の記事についてのツイートが流れてきました。
この記事の内容については、ChatGPTをはじめとするAIによるテストの可能性を示した素晴らしい内容だと思います。
ですが、果たして"今時点(元記事の執筆時点)の"出力結果*1が実用に耐えうるものになっているのか検討し、提示する必要もあると感じました*2。
そこで本記事では、テストエンジニアである私の回答例と"今時点の"AIの出力結果を比較しギャップを示すことを目的とします*3。
決して、AIによるテスト自動生成の進化自体を否定している訳ではないことを念頭にお読みいただければと思います。
結論
本記事では、"今時点の"AIの出力結果に対して、以下の結論を導き出しています。
- 状態遷移図のテスト設計の題材では、根幹となる機能に関する不具合が含まれていた
- デシジョンテーブルのテスト設計の題材では、デシジョンテーブルを表現できていないように見える
- 境界値分析のテスト設計の題材では、コードの保守性があまり良くないように見える
- 今時点のAIが作成できているのはテスト活動の一部である
目次
- はじめに 〜記事執筆のきっかけ〜
- 結論
- 目次
- 比較対象
- 「3.1 ストップウォッチの動作」の比較結果
- 「2.1 1杯目のビールの価格」の比較結果
- 「1.1 温度によって表示を変えるペット用室温系」の比較結果
- さいごに〜AIが作成を担っている範囲〜
比較対象
比較は元記事に書かれている以下の3つの仕様に対する成果物を題材とします。これらは全てソフトウェアテスト技法練習帳に掲載されています。本記事内での掲載順は、特に重要な課題があった順となります。
- 3.1 ストップウォッチの動作
- 2.1 1杯目のビールの価格
- 1.1 温度によって表示を変えるペット用室温系
使用する出力結果
AIの出力結果は、元記事の出力結果をそのまま引用します。
比較する出力結果は、私が問題を読んで書いた成果物です*4。
「3.1 ストップウォッチの動作」の比較結果
AIの出力結果
AIの出力結果は以下です。

私の成果物
私が書いた状態遷移図は以下です。

また、私は状態遷移図だけでなく状態遷移表とテストケースも作成しました*5。


検証結果
AIが状態遷移図とともに出力した実装物(元記事に記載あり)に対して、私が作成したテストケースを実施したところ、1件の不具合を発見しました。

不具合内容は「一時停止中にスタートボタンを押下すると、経過時間の続きからカウントアップするのではなく、0:00からカウントアップしてしまう」というものです。
これはストップウォッチの根幹となる部分の機能を損なっているといえるでしょう。
なぜこのような欠陥が埋め込まれてしまったのか考察したいのですが、本文中に書くと記事が長くなってしまうので注釈に記載します*6。
「2.1 1杯目のビールの価格」の比較結果
AIの出力結果
AIの出力結果は以下です。

私の成果物
私が書いたデシジョンテーブルは以下です。

検証結果
元記事では、「見た目にはわかりやすいのですが、少々理解しにくい構造であることが難点です。」と書いています。ですが個人的にはデシジョンテーブルの目的を果たす形式での記述になっていないように見えます。
デシジョンテーブル(決定表)は、以下のように定義されています。
問題の記述において起こり得るすべての条件と,それに対して実行すべき動作とを組み合わせた表。(JIS X 0125:1986 より)
また、動作部(アクション)は以下のように定義されています。表記方法ではなく、動作部ではどんな意味を持たす表記を目指しているのかに注目して引用箇所を見てください。
アクション:
• X:アクションが発生することを意味する(Y、T、または 1 とも記述する)。
• 空白:アクションが発生しないことを意味する(-、N、F、または 0 とも記述する)。
(ISTQBテスト技術者資格制度Foundation Level シラバス 日本語版 Version 2018V3.1.J03 より)
つまり、デシジョンテーブルは条件部と動作部に分かれ、動作部ではどの動作が行われるか表現することが目的といえます。
しかし、AIの出力結果は「何が条件部で何が動作部なのか分からない」「どの動作を行うのか表現するという目的が達成できていない」ように見えます。
もしも、AIの出力結果の形式で、デシジョンテーブルの目的に沿うように表現するとしたら、以下のような形を提案します*7。

「1.1 温度によって表示を変えるペット用室温系」の比較結果
AIの出力結果
AIの出力結果は以下です。(元記事より抜粋)
describe("室温計のプログラム", () => { test("室温が24.0℃未満の場合、「寒い」と表示される", () => { expect(getTemperatureMessage(23.9)).toBe("寒い"); }); test("室温が24.0℃の場合、「快適」と表示される", () => { expect(getTemperatureMessage(24.0)).toBe("快適"); }); test("室温が24.1℃の場合、「快適」と表示される", () => { expect(getTemperatureMessage(24.1)).toBe("快適"); }); test("室温が25.9℃の場合、「快適」と表示される", () => { expect(getTemperatureMessage(25.9)).toBe("快適"); }); test("室温が26.0℃の場合、「暑い」と表示される", () => { expect(getTemperatureMessage(26.0)).toBe("暑い"); }); test("室温が26.1℃の場合、「暑い」と表示される", () => { expect(getTemperatureMessage(26.1)).toBe("暑い"); }); });
私の成果物
私が書いたテストコードは以下です。
describe("室温計のプログラム", () => { describe("室温が24.0℃未満の場合、「寒い」と表示される", () => { it("室温が23.9℃の場合、「寒い」と表示される", () => { expect(getTemperatureMessage(23.9)).toBe("寒い"); }); }); describe("室温が24.0℃以上26.0℃未満の場合、「快適」と表示される", () => { it("室温が24.0℃の場合、「快適」と表示される", () => { expect(getTemperatureMessage(24.0)).toBe("快適"); }); it("室温が25.9℃の場合、「快適」と表示される", () => { expect(getTemperatureMessage(25.9)).toBe("快適"); }); }); describe("室温が26.0℃以上の場合、「暑い」と表示される", () => { it("室温が26.0℃の場合、「暑い」と表示される", () => { expect(getTemperatureMessage(26.0)).toBe("暑い"); }); }); });
検証結果
AIの作成物と私の成果物を比べると、以下の2点が異なります。
- 境界値分析の選択が2値か3値か
- 「未満」「以上」の表記があるかどうか(振る舞いを表現しているか、単にコードを表現しているか)
実際の動作としてはどちらも正しく動きますが、テストコードの保守性という点では、AI作成よりも私が作成したものの方が良いかと思います*10*11。
さいごに〜AIが作成を担っている範囲〜
ここまで、"今時点でのAIの"出力結果に対して、さまざまな気になる点を提示しました。しかし、これはあくまでも"今時点の"出力結果です。近い将来、このような部分は改善されていくことでしょう。
ただし、テストで考えるところは今回議論しているような部分だけではありません。
例えば、JSTQBでは、以下のようにテストプロセスを示しています。

このうち、今回行っていたのは主に「テスト設計」「テスト実装」の部分です。
「テスト分析」はどうなっていたかというと、実はAIへの指示命令の文章内(書籍に書いてある問題文内)に入っていました。例えば、「2.1 1杯目のビールの価格」の問題文の最後には以下のように書いてあります。
1杯目のビールの価格を表すデシジョンテーブルを作成してください。
これは、以下の指定をしていることになります。
- 1杯目のビールの価格に関するテストを行わなくてはいけない
- 2杯目以降のビールの価格に関するテストは行わなくて良い
- ハッピーアワーの時間帯に関するテストは行わなくて良い
- クーポンの同時使用枚数に関するテストは行わなくて良い
- ビールの注がれる量に関するテストは行わなくて良い
- デシジョンテーブルを使用しなくてはいけない
- 状態遷移テストを行わなくて良い
- 境界値分析を行わなくて良い
幾多ある確認したいことに対して「1杯目のビールの価格」という確認項目を指定し、幾多あるテスト設計技法のうち「デシジョンテーブル」を指定しています。
この「何を確認するか」「そのためにどんなテスト設計技法を用いれば良いか」といった部分は、まだまだAIに考えさせるのが難しい分野かなと思っています。
また、デシジョンテーブルの例や、境界値分析における振る舞いの表現のように、「物事を俯瞰的に見て表現する」「ハイレベルテストケースで表現する」といった部分はまだ苦手なのかなと感じました。
なのでテストエンジニア以外の方(開発者など)は、元記事を読んで「それじゃあ、もうテストエンジニアは必要ないね」と思わない方が良いかと思います。
またテストエンジニアの方は、そう思われないように「普段、自分はどんなことをやっているのか」という話を今まで以上にきちんと説明すべきなのかもしれません。
そして何度も繰り返し述べますが、今回の記事は"今時点の"AIの出力結果に対しての記事です。今時点の評価をしつつ、今後のAIのテスト作成の進化を応援しています!
*1:あくまでも今時点での話です。本記事は、将来のAIの進化まで否定したいという意図はありません。
*2:将棋の世界では似たようなことが起きました。Bonanzaメソッドによって画期的にAIの実力が強くなった当初、「これって人間を超えたのでは?」と言われるようになりました。それに対して、将棋連盟は「電王戦」という一般人にも分かりやすい形でプロ棋士とAIとの現在地を示しました。さらに永瀬六段(当時)は、自分自身が明らかに優勢な段階で、AI側の不具合を指摘しました(角不成の件)。これと同じような話をする必要が今回の件もあるんじゃないだろうか、というのが本記事執筆のモチベーションの詳細です
*3:今回の記事に対するツッコミに予め回答しておきます。
【ツッコミ1】そうやってテストエンジニアとしての自尊心を保ちたいだけだろ→違います。むしろ、今回検討した結果でさえすぐにAIは乗り越えてくるのでは?とさえ思っていますし、そうなることを期待しています。
【ツッコミ2】「だからAIは使えない」と言いふらしたいんだろ→違います。あくまでも今時点のAIの出力結果を比較することを目的としています。AIによる自動生成を応援する気持ちと、今時点のAIの作成物を評価する行動は両立すると思ってます。「ああ、もう今時点でテストはAIに任せれば全てOKだね」と思っていた方々が、本記事を読んで少しでも考え方を変えてもらえればと思っています
*4:本当はソフトウェアテスト技法練習帳の書籍に書かれている回答例を示した方が良いかもしれませんが、著作権の問題でどこまで載せて良いか不安になったので、あくまでも私が書いたものを示します。
*5:なお、ここで作成したテストケースは、状態遷移表を元に作成したものであり、自分でテストする場合は、実施手順の効率を考えて、手順の並び替え等を行います
*6:なぜAIがこのような欠陥を埋め込み、発見できなかったのか考察します。
【欠陥を埋め込んだ原因】仕様(問題文)には期待値を明確に記載していなかった
状態遷移図はあくまでも状態がどのように変わるのかを明記しているものです。一方で、それぞれの状態でどのような動作になっていれば良いのかが曖昧なままでした。
ちなみに元の仕様では以下のように記述されています。何かしら別の動作になるように見えますが、具体的にどのように動作するのかは明確に記載されていません。
計測準備中にスタートボタンを押すと計測が始まります
一時停止中にスタートボタンを押すと再開します
そのため、「計測中への状態の変化=カウントアップを始める=0:00から増やしていく」と勘違いしてしまった可能性があります。
もっと明確に定義を記載すれば、AIによる生成でも今回のような不具合を埋め込まずに済んだかもしれません。元記事で「プロンプトの最適化(プロンプトエンジニアリング)」と表現している分野の発展が必要となる未来になるかも…?
【欠陥を発見できなかった原因】テストコード内で再開時の時間経過のテストをしていなかった
今回のAI作成のテストコードの確認内容を日本語で表記すると以下のようになります。
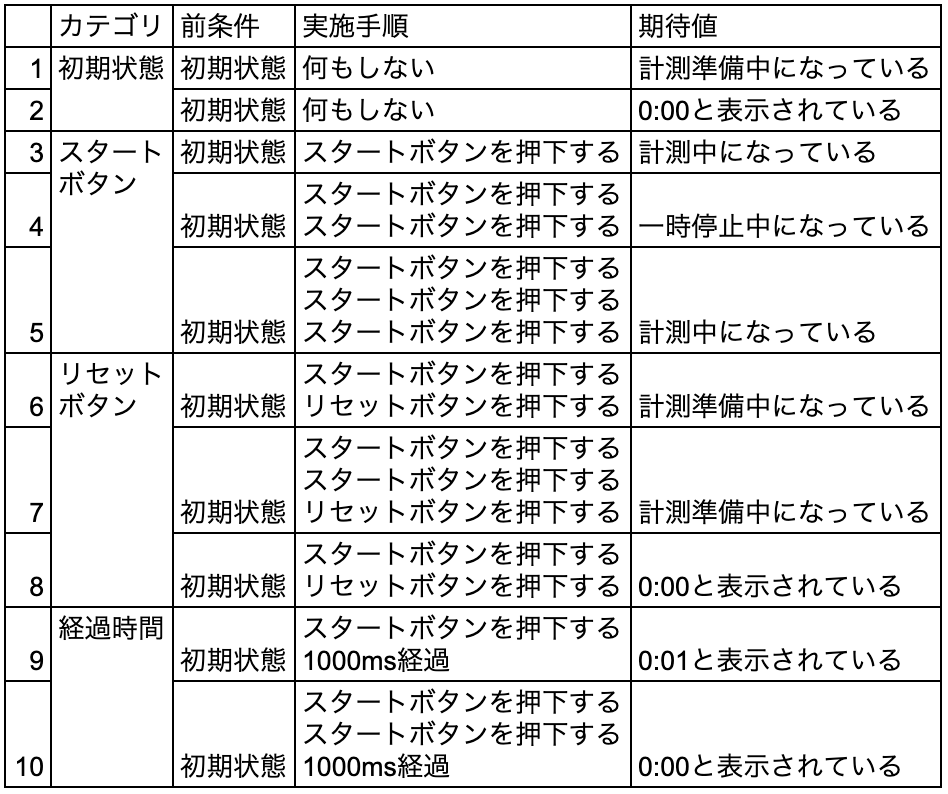
この中で、時間経過については「開始時」「一時停止時」の2つしか確認できていませんでした。そのため、欠陥を発見することもできていません。
*7:規格で定義されているデシジョンテーブルの書き方と比べて、行と列が転置している点については、現状では仕方ないかなと思っています。規格で定義されているデシジョンテーブルは1列ごとにテストパターンが書かれています。一方、ChatGPTは1行ごとに出力されるため、テストパターンを1行ごとに記述する現在の形にならざるを得ないと思うので。
*8:私が作成したものは2値の境界値分析をしていますが、AIが作成したものは3値の境界値分析をしています。2値と3値の境界値分析について詳しくは、akiyamaさんのブログ投稿を参考にしてください。
ここでは詳しい説明を割愛しますが、2値より3値の方がより注意深くテストしているといえます。私が2値の境界値分析をしている理由は、「2値では発見できないが3値では初めて発見できる不具合が今回の場合はあまり多くないのではないか」「2値の方が単純にテストコードの作成/保守コストが少ない」という2点です。
*9:AI作成のテストコードでは境界値のどのような部分を調べたいのかを読み取ることが難しいです。
数年後に機能の改修が入り、例えば"室温が26.0℃の場合、「暑い」と表示される"というテストコードだけ失敗した場合、このテストコードは何を確認したいコードなのか読み取ることが難しくなります。
この点について詳しくは、RAKUSさんのブログ投稿が分かりやすいので、そちらを参考にしてください。
*10:私自身が作成し、私が「良い」と判断しているので、読者の皆さんの意見を聞きたいところです
*11:そもそも、AI作成の場合、毎回新たに作れば良いので保守性を考える必要がないという意見もあるかもしれません。